
Table of Contents
You might have searched for web scraping and got solutions that use Cheerio and axios/fetch.
The problem with this approach is we cannot scrape dynamically rendered web pages or client-side rendered web pages using Cheerio.
To scrape such webpages, we need to wait for the page to finish rendering. In this article, we will see how to wait for a particular section to appear on the page and then access that element.
Initial setup
Consider the page https://cra-crawl.vercel.app. Here, we have a title and a list of fruits.
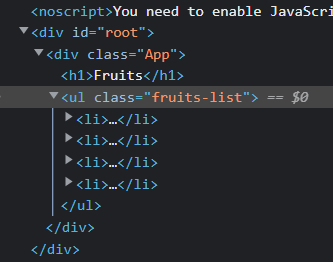
If you inspect the page, you will see that the heading is inside the h1 tag and the list has a class named 'fruits-list'. We will be using these 2 elements to access the heading and the list of fruits.
Creating Node project
Create a directory called node-react-scraper and run the command npm init -y. This will initialize an npm project.
Now install the package puppeteer using the following command:
1npm i puppeteer
Puppeteer is a headless browser (Browser without UI) to automatically browse a web page.
Create a file called index.js inside the root directory.
Reading the heading
We can use the puppeteer as follows in index.js
1const puppeteer = require("puppeteer")23// starting Puppeteer4puppeteer5 .launch()6 .then(async browser => {7 const page = await browser.newPage()8 await page.goto("https://cra-crawl.vercel.app/")9 //Wait for the page to be loaded10 await page.waitForSelector("h1")1112 let heading = await page.evaluate(() => {13 const h1 = document.body.querySelector("h1")1415 return h1.innerText16 })1718 console.log({ heading })1920 // closing the browser21 await browser.close()22 })23 .catch(function (err) {24 console.error(err)25 })
In the above code, you can see that we are waiting for the h1 tag to appear on the page and then only accessing it.
You can run the code using the command node index.js.
Accessing the list of fruits
If you want to access the list of fruits, you can do so by using the following code:
1const puppeteer = require("puppeteer")23// starting Puppeteer4puppeteer5 .launch()6 .then(async browser => {7 const page = await browser.newPage()8 await page.goto("https://cra-crawl.vercel.app/")9 //Wait for the page to be loaded10 await page.waitForSelector(".fruits-list")1112 let heading = await page.evaluate(() => {13 const h1 = document.body.querySelector("h1")1415 return h1.innerText16 })1718 console.log({ heading })1920 let allFruits = await page.evaluate(() => {21 const fruitsList = document.body.querySelectorAll(".fruits-list li")2223 let fruits = []2425 fruitsList.forEach(value => {26 fruits.push(value.innerText)27 })28 return fruits29 })3031 console.log({ allFruits })32 // closing the browser33 await browser.close()34 })35 .catch(function (err) {36 console.error(err)37 })
Here we are using the querySelectorAll API to get the list of nodes containing fruits. Once we get the list, we are looping through the nodes and accessing the text inside it.
Source code
You can view the complete source code here.
If you have liked article, do follow me on twitter to get more real time updates!